Pre-reqisite:
- Single node Hadoop should be up and runing
Please follow my previous blog on single node Hadoop setup if it not ready for you
Hadoop Single Node Setup
- Down load and install Eclipse from below location if Eclipse does not exist
wget http://www.eclipse.org/downloads/download.php?file=/technology/epp/downloads/release/kepler/SR2/eclipse-jee-kepler-SR2-linux-gtk-x86_64.tar.gz
bhupendra@ubuntu:/home/hduser/eclipse$ ./eclipse
Step 1:
Start Eclipse and create New Java Project as below

Step 2: Write Wordcount Driver class

Step 3: Replace below code from autogenerated WordCount.java class
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WordCount extends Configured implements Tool{
public int run(String[] args) throws Exception
{
//creating a JobConf object and assigning a job name for identification purposes
JobConf conf = new JobConf(getConf(), WordCount.class);
conf.setJobName("WordCount");
//Setting configuration object with the Data Type of output Key and Value
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
//Providing the mapper and reducer class names
conf.setMapperClass(WordCountMapper.class);
conf.setReducerClass(WordCountReducer.class);
//conf.setMapperClass(WordCountMapper.class);
//conf.setMapperClass(WordCountReducer.class);
//We wil give 2 arguments at the run time, one in input path and other is output path
Path inp = new Path(args[0]);
Path out = new Path(args[1]);
//the hdfs input and output directory to be fetched from the command line
FileInputFormat.addInputPath(conf, inp);
FileOutputFormat.setOutputPath(conf, out);
JobClient.runJob(conf);
return 0;
}
public static void main(String[] args) throws Exception
{
// this main function will call run method defined above.
int res = ToolRunner.run(new Configuration(), new WordCount(),args);
System.exit(res);
}
}
Step 4: Create new WordCountMapper class
Replace with below codes
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
public class WordCountMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable>
{
//hadoop supported data types
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
//map method that performs the tokenizer job and framing the initial key value pairs
// after all lines are converted into key-value pairs, reducer is called.
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException
{
//taking one line at a time from input file and tokenizing the same
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
//iterating through all the words available in that line and forming the key value pair
while (tokenizer.hasMoreTokens())
{
word.set(tokenizer.nextToken());
//sending to output collector which inturn passes the same to reducer
output.collect(word, one);
}
}
}
Step 5: Create WordCountReducer Class
And replace with below code
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
public class WordCountReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable>
{
//reduce method accepts the Key Value pairs from mappers, do the aggregation based on keys and produce the final out put
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException
{
int sum = 0;
/*iterates through all the values available with a key and add them together and give the
final result as the key and sum of its values*/
while (values.hasNext())
{
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
Step 6: If Above java classes are not having any syntax error, the corresponding class file will be generated automatically as follows:



Step 9:
Now right click on project and select Export. under Java, select Runnable Jar.
In Launch Config - select the config fie you created in Step 8 (WordCountConfig).
Select an export destination ( lets say desktop.)
Under Library handling, select Extract Required Libraries into generated JAR and click Finish.










- Single node Hadoop should be up and runing
Please follow my previous blog on single node Hadoop setup if it not ready for you
Hadoop Single Node Setup
- Down load and install Eclipse from below location if Eclipse does not exist
wget http://www.eclipse.org/downloads/download.php?file=/technology/epp/downloads/release/kepler/SR2/eclipse-jee-kepler-SR2-linux-gtk-x86_64.tar.gz
bhupendra@ubuntu:/home/hduser/eclipse$ ./eclipse
Step 1:
Start Eclipse and create New Java Project as below

Step 2: Write Wordcount Driver class

import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WordCount extends Configured implements Tool{
public int run(String[] args) throws Exception
{
//creating a JobConf object and assigning a job name for identification purposes
JobConf conf = new JobConf(getConf(), WordCount.class);
conf.setJobName("WordCount");
//Setting configuration object with the Data Type of output Key and Value
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
//Providing the mapper and reducer class names
conf.setMapperClass(WordCountMapper.class);
conf.setReducerClass(WordCountReducer.class);
//conf.setMapperClass(WordCountMapper.class);
//conf.setMapperClass(WordCountReducer.class);
//We wil give 2 arguments at the run time, one in input path and other is output path
Path inp = new Path(args[0]);
Path out = new Path(args[1]);
//the hdfs input and output directory to be fetched from the command line
FileInputFormat.addInputPath(conf, inp);
FileOutputFormat.setOutputPath(conf, out);
JobClient.runJob(conf);
return 0;
}
public static void main(String[] args) throws Exception
{
// this main function will call run method defined above.
int res = ToolRunner.run(new Configuration(), new WordCount(),args);
System.exit(res);
}
}
Step 4: Create new WordCountMapper class
Replace with below codes
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
public class WordCountMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable>
{
//hadoop supported data types
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
//map method that performs the tokenizer job and framing the initial key value pairs
// after all lines are converted into key-value pairs, reducer is called.
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException
{
//taking one line at a time from input file and tokenizing the same
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
//iterating through all the words available in that line and forming the key value pair
while (tokenizer.hasMoreTokens())
{
word.set(tokenizer.nextToken());
//sending to output collector which inturn passes the same to reducer
output.collect(word, one);
}
}
}
Step 5: Create WordCountReducer Class
And replace with below code
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
public class WordCountReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable>
{
//reduce method accepts the Key Value pairs from mappers, do the aggregation based on keys and produce the final out put
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException
{
int sum = 0;
/*iterates through all the values available with a key and add them together and give the
final result as the key and sum of its values*/
while (values.hasNext())
{
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
Step 6: If Above java classes are not having any syntax error, the corresponding class file will be generated automatically as follows:
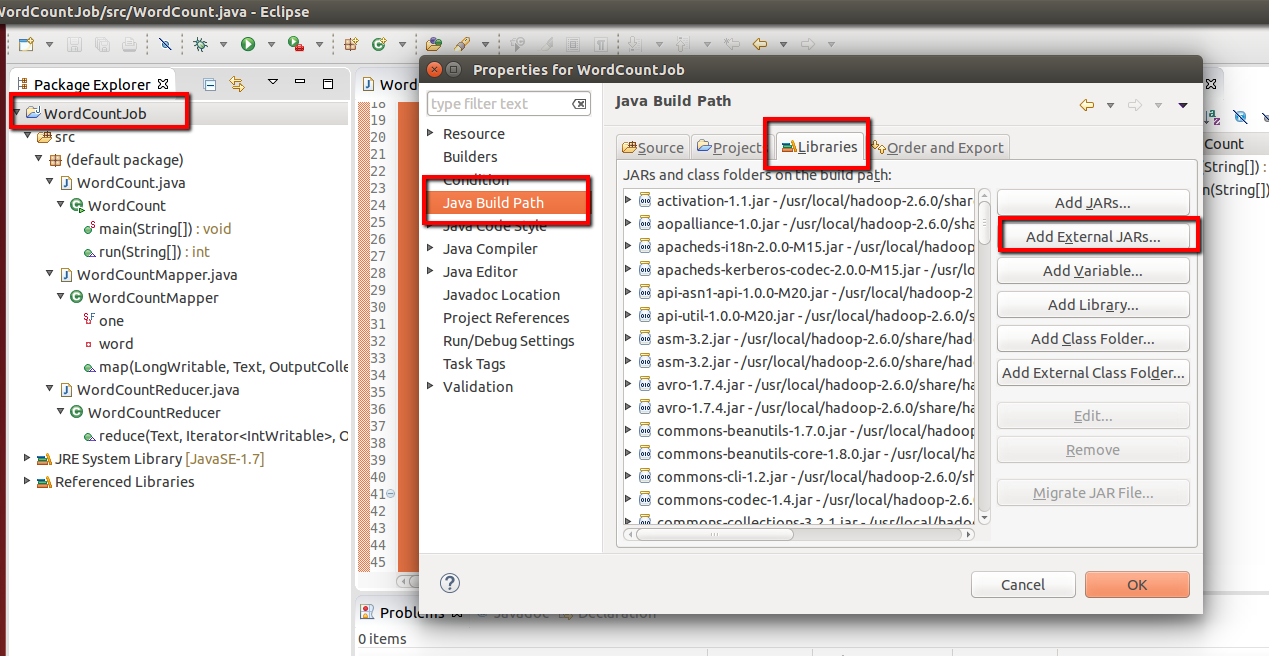
Step 7:
Additionally before step 6, we have to add dependencies by adding external libraries from hadoop
Follow the below screenshots and added external jar from path
( in my case its /usr/local/hadoop-2.6.0/share/hadoop/common and /usr/local/hadoop-2.6.0/share/hadoop/mapreduce )
{HADOOP_HOME}/share/hadoop/common
{HADOOP_HOME}/share/hadoop/common/lib
{HADOOP_HOME}/share/hadoop/mapreduce
{HADOOP_HOME}/share/hadoop/yarn
{HADOOP_HOME}/share/hadoop/hdfs
Step 8:
Now Click on the Run tab and click Run-Configurations. Click on New Configuration button and fill the Name, Project Name and Main Class per screen-shots

Step 9:
Now right click on project and select Export. under Java, select Runnable Jar.
In Launch Config - select the config fie you created in Step 8 (WordCountConfig).
Select an export destination ( lets say desktop.)
Under Library handling, select Extract Required Libraries into generated JAR and click Finish.


Step 10:
- Switch to hduser $sudo su hduser
- Remove temp file generated to gracefully start all required hadoop deamons like namenode, datanode, resourcemange, applicaiton manager, 2ndory Name node.
temp file location is based on tmp file location defined in one of the hadoop configuration file core-site.xml

Step 11: Format name node using below command
#hadoop namenode -format and output will be something like below

Step 12: start process and check if required deamon has been started gracefully or not. Refer below screen and commands for the same

Please note, if temp files are there and not removed, few of deamons will not be started properly.
Step 13:
Make a hdfs directory ( Note: These directories are not listed when ls is used in the terminal and they are also not visible in the File Browser ) - hadoop dfs -mkdir -p /usr/local/hadoop-2.6.0/input
Copy the sample input text file into this hdfs directory - hadoop dfs -copyFromLocal /home/bhupendra/workspace/sample1.txt /usr/local/hadoop-.2.6.0/input
Change directory to run an example Wordcount program using jar file. NOTE: Don't create output folder out1, it will be created and every time you run an example, give a new directory. These directories are not visible with ls command in terminal.
hadoop jar wordcount.jar /usr/local/hadoop/input /usr/local/hadoop/output

<< I will fix the above issue latter, as this issue causing unable to run hadoop command to create directory and copyfile from local to hdfs director"input"
to run the programme, I have created input directory using usula mkdir command and copied file using cp command >>
Error:
hadoop fs -ls
15/01/30 17:03:49 WARN util.NativeCodeLoader: Unable to load native-hadoop
ibrary for your platform... using builtin-java classes where applicable
ls: `.': No such file or directory
Fix1
well, your problem regarding
ls: '.': No such file or directory' is because there is not home dir on HDFS for your current user. Tryhadoop fs -mkdir -p /user/[current login user]
Then you will be able to
hadoop fs -ls
Fix2
go to hadoop conf path
hduser@ubuntu:/usr/local/hadoop-2.6.0/etc/hadoop
vi hadoop-en.sh and add following lines
export HADOOP_PREFIX=/usr/local/hadoop-2.6.0
export HADOOP_HOME=/usr/local/hadoop-2.6.0
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export YARN_HOME=${HADOOP_HOME}
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
< Please note hadoop-env.sh environment variable overrides variables in side .bashrc file. Hence it is mandatory to add above lines in hadoop-env.sh file>
Step 14:
run the job using below command
hadoop jar WordCount.jar /usr/local/hadoop-2.6.0/input /usr/local/hadoop-2.6.0/output
Step 15
Browse the Hadoop GUI
http://localhost:50070/dfshealth.html#tab-overview
Step 16:
Browse the output file
http://localhost:50070/explorer.html#/usr/local/hadoop-2.6.0/output
Step 17:
Stop all deamons if you are done with job
http://localhost:8088/cluster
hduser@ubuntu:/usr/local/hadoop-2.6.0/etc/hadoop$ hadoop fs -ls hdfs://localhost:54310
Found 1 items
drwxr-xr-x - hduser supergroup 0 2015-07-17 10:42 hdfs://localhost:54310/user/hduser/input
hduser@ubuntu:/usr/local/hadoop-2.6.0/etc/hadoop$
Please mention which local files should be copied to the input directory.
ReplyDeleteThanks. This helped me!!!
ReplyDeleteHappy to know...:)
DeleteMap reducing concept is the important one in hadoop.In this blog it explains clearly and easy to understand.
ReplyDeleteBesant Technologies Reviews | Besant Technologies Reviews
Its very helpful and simple tutorial ..
ReplyDeleteNice Blog. Thanks for sharing
ReplyDeleteCCNP training in Chennai
Thanks for sharing this article.. You may also refer http://www.s4techno.com/blog/2016/07/11/hadoop-administrator-interview-questions/..
ReplyDeleteHello,
ReplyDeleteHello,
The MapReduce programming model is straightforward, and borrows from the simplicity of functional programming. In the MapReduce programming model, the developer expresses the computation goal as the implementation of two primitive functions: map() and reduce().
It's really a nice experience to read your post. Thank you for sharing this useful information.
ReplyDeleteSAP Abap On Hana Training
Exchange Server Training
Attributes Of QuickBooks Support Number simple to get a sum of benefits with QuickBooks. Proper analyses are done first. The experts find right out of the nature linked to trouble. You will definately get an entire knowledge as well. The support specialist will identify the difficulty. The deep real cause may very well be found out. Each of the clients are extremely pleased with us. We've got many businessmen who burn off our QuickBooks Techincal Support service. It is simple to come and discover the perfect service for your requirements.
ReplyDeleteYou'll find so many fields it covers like creating invoices, managing taxes, managing payroll etc. However exceptions are typical over, sometimes it makes the down sides and user wants QuickBooks Support Number Service help.
ReplyDeleteQuickBooks Enterprise Tech Support Number Edition is not only an accounting software but a complete ERP solution within itself. Now days, it absolutely was evident that Medium Scale Business and Industry specific business like Manufacturing, Contractors, Wholesalers, Retail, Professional Services etc. invests good amount of money regarding the accounting software to make certain data accuracy, timely delivery of information so they will be able to give attention to their particular workfare to boost the productivity and therefore increased business. QuickBooks Enterprise edition is a one stop seek out such style of business and QuickBooks Enterprise Support may be the one stop solution provider for detecting and fixing QuickBooks Enterprise Accounting problems and technical issues.
ReplyDeleteDial QuickBooks Payroll tech support number to ask for QuickBooks enhanced payroll support to fix payroll issues. We work for startups to small-scale, medium-sized to multinational companies. At AccountWizy, you will find well-qualified and trained accountants, Proadvisors who can handle such errors. QuickBooks Payroll Support Number is a way of contacting us for Intuit product and QuickBooks Payroll subscription.
ReplyDeleteWe all know that the complexity of errors varies from organization to organization. You don’t have to worry for that as our team is well-aware of the latest software issues and complications. Also, they keep themselves updated with the latest technology and errors introduced into the software on regular period of time. You simply need to interact with us on phone by dialing Intuit QuickBooks Phone Number.
ReplyDeleteThe QuickBooks Payroll Technical Support Phone Number at site name is held responsible for removing the errors that pop up in this desirable software. We care for not letting any issue can be purchased in in the middle of your work and trouble you in undergoing your tasks.
ReplyDeleteQuickBooks Tech Support Number it is a big challenge for business organizations to obtain a good means to fix manage their business accounts in a convenient way. To utilize a fruitful organization, you ought to have a robust account management process to cultivate and lead.
ReplyDeleteEnterprise support number offers you proper assistance whenever you need it. You are able to avail Enterprise Support using E-mail yet QuickBooks Enterprise Support Number US serves to be the ideal form of assistance. Here our experts will answr fully your call and offer you perfect solutions on QuickBooks Enterprise resolving all of the issues faced by you.
ReplyDeleteThe web is stuffed with faux numbers WHO decision themselves the QuickBooks Support Provider. you’ll value more highly to dial their variety however that would be terribly risky. you’ll lose your QuickBooks Company file or the code itself. dig recommends dialing solely the QuickBooks Technical Support Phone Number
ReplyDeleteYou have got the best option option for connecting your field staff and your in-house staff in order to market closeness and harmony amongst both the groups.
ReplyDeleteIn addition QuickBooks Enterprise Support Phone Numbe enables you to work from anywhere at any point of that time period.
The principal intent behind QuickBooks Support number is to offer the technical help 24*7 so as in order to prevent wasting your productivity hours. This is certainly completely a toll-free QuickBooks Support Phone Number client Service variety that you won’t pay any call charges.
ReplyDeleteAny errors related to QuickBooks software can damage important computer data you could fix them through Intuit QuickBooks Support Number and QuickBooks 24/7 Support will be there to simply help. We solve, manage, and help you to definitely cope with any technical problems and guarantees that this program is useful.
ReplyDeleteQuickBooks Support functions: A business must notice salaries, wages, incentives, commissions, etc., this has paid towards the employees in a time period. Above all may be the tax calculations must be correct and based on the federal and state law.
ReplyDeleteOur backing team is dedicated enough to bestow you with end-to-end QuickBooks Tech Support Number solutions once you want to procure them for each and every QuickBooks query.
ReplyDeleteQuickbooks Technical support customer support executives that actually make use of you on QuickBooks Support Number are responsible to manage every Quickbook technical issue that creates in QuickBooks software.
ReplyDeleteQuickBooks Support – Inuit Inc has indeed developed an excellent software product to manage the financial needs associated with the small and medium-sized businesses. The name regarding the application is Support For QuickBooks. QuickBooks, particularly, doesn't have any introduction for itself. But one who is unknown to this great accounting software, we wish one to give it a try.
ReplyDeleteIntuit is perhaps all concerning User expertise which explains why they need creating dedicated QuickBooks Technical Support Number variety; Users will dial the fee number just in case they usually have any facilitate in regards to the code.
ReplyDeleteQuickBooks Enterprise Support Number assists anyone to overcome all bugs from the enterprise types of the applying form. Enterprise support team members remain available 24×7 your can buy facility of best services.
ReplyDeleteThis phone number is QuickBooks Support Phone Number Best Phone Number because like you used this contact information over the last and gave us feedback. Common problems addressed by the customer care unit that answers calls to include Returns, Cancel order, Change order, Technical support, Track order and other customer service issues. Rather than trying to call QuickBooks we recommend you tell us what issue you are having and then possibly contact them via phone or web or chat. In total, QuickBooks has 1 phone number. It's not always clear what is the best way to talk to QuickBooks representatives, so we started compiling this information built from suggestions from the customer community. Please keep sharing your experiences so we can continue to improve this free resource.
ReplyDeleteThis software has equipped almost all the QuickBooks users with a great deal of strength that they feel accomplished. QuickBooks Payroll Technical Support Phone Number is certainly one such software that includes instilled the appropriate feeling of making use of your money and its particular management in the most effective manner.
ReplyDelete